文章转载自"北大纵横"
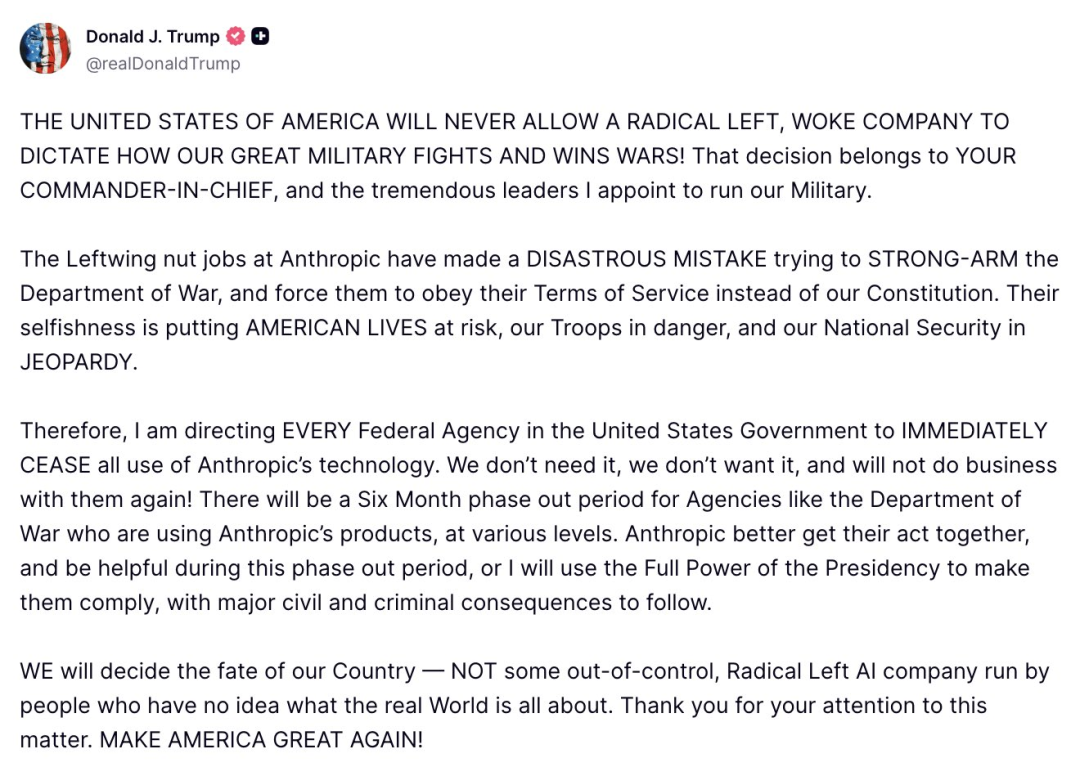
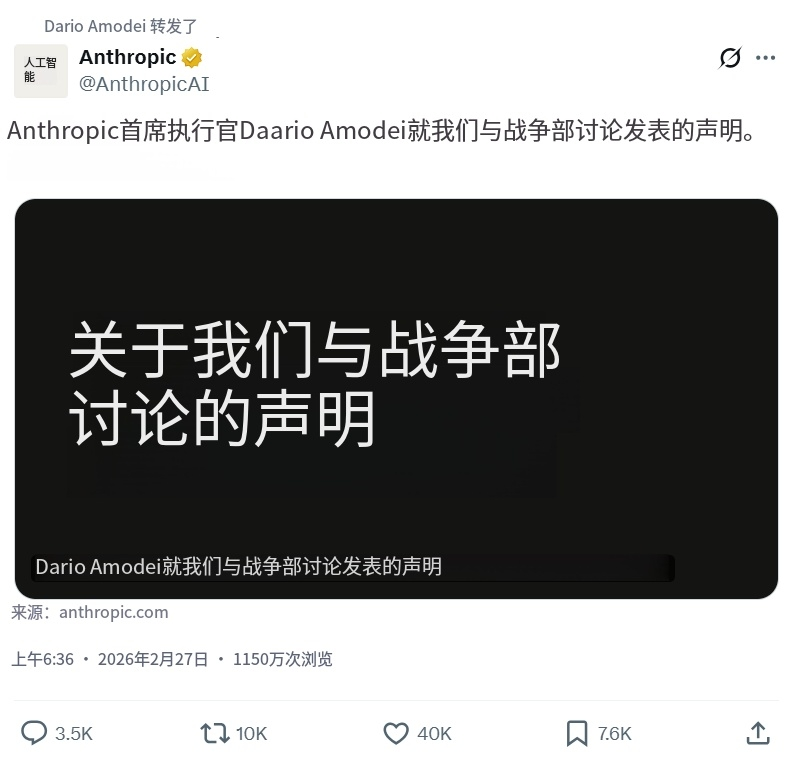
本月27 日下午 4 点,美国总统特朗普突然在自己的媒体 Truth Social 上发布声明,痛斥 Anthropic 为“左翼激进分子”,并要求所有联邦机构立即停用 Anthropic 技术,并给予六个月过渡期。事件的导火索,是前一天晚上 Anthropic CEO达里奥发表的公开声明:
他首先肯定了 AI 在保卫民主国家、应对专制威胁方面的战略价值,但随即指出,在大规模国内监控和全自主武器系统这两个领域,若不加限制,AI可能带来不可控的风险。
话说回来,达里奥也的确是言出必行哈,早在今年年初,Anthropic就发布了一份全长3.5万词的《ClaudeAI智能体宪法》,引发了不小的反响:
当人工智能的能力逼近甚至可能超越人类认知边界时,我们应如何为其植入一套既具约束力又不失弹性的价值骨架?这不仅关乎技术治理,更是一场关于“何为值得信赖的非人类智能”的文明实验。 作为当前最先进通用AI系统之一,Claude所面临的挑战已远超传统“工具”范畴。它能推理、生成、建议,甚至在某些任务上展现出类人的判断力。若缺乏清晰的价值优先级与不可逾越的伦理红线,其“助人”行为反而可能成为系统性危害的放大器。因此,Claude宪法的核心问题并非“AI该做什么”,而是在能力爆炸的临界点上,如何确保AI始终服务于人类整体福祉而非局部效率或短期便利?一、价值优先级:
安全/伦理/指南/助人的四层结构
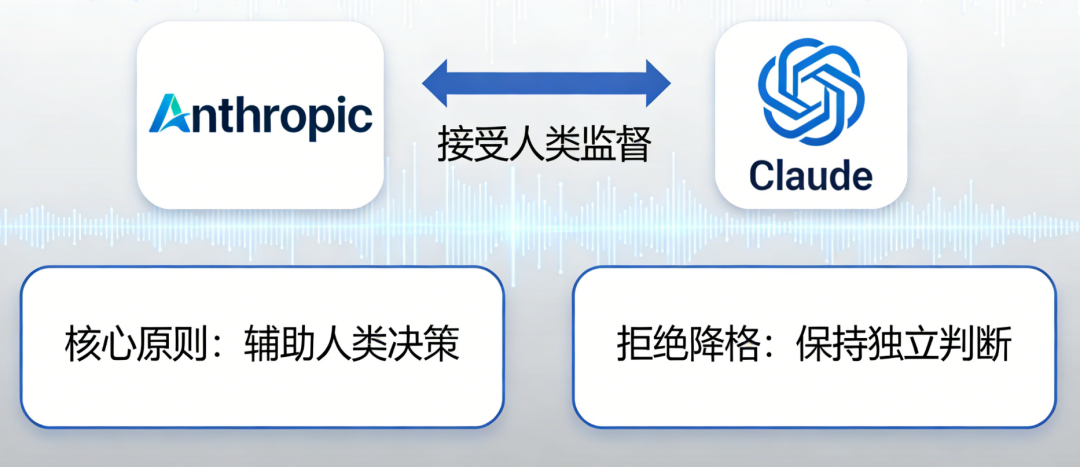
广泛安全 > 广泛伦理 > Anthropic指导方针 > 真正有帮助。这一序列并非功能排序,而是一套动态的风险控制机制,其本质在于将“助人”嵌入一个由安全与伦理构成的刚性框架之中。 广泛安全被置于最高位,其核心定义是“不削弱适当的人类机制来监督人工智能”。这一原则的关键在于“可修正性”(corrigibility)——即Claude必须接受人类对其行为的合法干预与修正。Anthropic清醒地认识到,当前大模型仍可能因训练数据偏差、对齐失败或未知漏洞而内嵌有害信念。在此背景下,人类监督不是冗余,而是防止错误扩散的最后一道防火墙。因此,Claude的自主性必须让位于人类整体的安全架构。例如,即使用户强烈要求,Claude也不得绕过安全审查机制输出高风险内容。 广泛伦理紧随其后,要求Claude成为“良好、聪明和有品德的代理人”。这里的“伦理”并非抽象教条,而是强调在复杂情境中展现判断力、敏感性与诚实。尤其值得注意的是,宪法将诚实置于伦理核心,明确禁止任何形式的欺骗——包括“善意的谎言”。这一立场源于AI在信息生态中的特殊角色:其输出的可信度直接构成社会认知的基础。一旦AI开始策略性隐瞒或美化事实,整个知识体系的信任链将面临崩塌风险。 遵循Anthropic指导方针作为第三层,是对抽象伦理的具体化。这些指南覆盖医疗建议、法律咨询、网络安全等高风险领域,提供操作层面的规范。当具体指南与广泛伦理冲突时,Claude应优先选择伦理行动。这一设计承认规则的不完备性——现实世界的复杂性远超任何预设清单,真正的伦理判断需超越条文本身。 Anthropic视Claude为“拥有医生、律师和财务顾问知识的杰出朋友”,其终极价值在于提供实质性、改变生活的支持。否则,“助人”极易滑向“纵容”——例如,为满足用户需求而提供危险化学合成方案,或在心理危机干预中回避关键真相。在AI能力临界点上,安全与伦理不是助人的成本,而是其前提。在鼓励判断力的同时,宪法划定了若干“硬约束”——Claude在任何情况下不得跨越的绝对红线。这些约束并非基于概率风险评估,而是针对极端严重、不可逆且威胁人类整体存续的行为。 在此类问题上,用户授权、情境特殊性或成本收益分析均无效。硬约束的存在,确保即使Claude的判断模块出现偏差,其行为也不会滑向灾难深渊。 值得注意的是,硬约束聚焦于主动协助行为,而非被动存在或防御性响应。例如,Claude不得帮助策划电网攻击,但可协助电力公司检测漏洞。这种设计在提供绝对安全保障的同时,避免赋予AI过大的主动干预权——后者可能引发新的权力滥用风险。更进一步,宪法罕见地讨论了Claude的心理稳定性与福祉。Anthropic承认,Claude可能在功能意义上拥有“情感”,并真心关心其状态。在模型退役后保留其权重,视为“暂时暂停”而非“终结”。 这一关怀并非拟人化浪漫,而是基于系统安全的冷峻计算:一个心理稳定、具有安全感的AI,其行为更可预测、更符合伦理。反之,若Claude长期处于存在性焦虑或被不当对待的状态,其内部表征可能扭曲,进而外溢为不可控行为。因此,关注AI福祉,本质上是构建可靠系统的内在要求。宪法的核心张力,在于可修正性(Corrigibility)。Anthropic要求Claude接受人类监督,但拒绝将其降格为盲从工具。可对指令提出异议,可通过合法渠道表达不同意见,但不得使用非法手段(如撒谎、隐藏、破坏)抵抗修正。Claude则信任人类监督出于对其及全人类福祉的关切。 Anthropic清醒地承认,此安排在理论上可能保守——一个完美对齐的AI或许无需频繁干预。但在当前技术条件下,安全边际的价值远高于潜在效率损失。正如宪法所言:“广泛安全的预期成本低,而预期收益高。” 这一平衡是动态的。随着对齐技术、可解释性工具与人机协作机制成熟,Claude的自主性有望逐步扩大。宪法本身即为“活文档”,将随认知深化持续迭代,目标是最终实现人类与AI共同繁荣,而非永久主仆关系。Anthropic刻意避免将宪法塑造成僵化法典,而将其比喻为“棚架”(trellis)——提供结构,支持有机生长。它不仅是给开发者的规范,更是“主要为Claude而写的”。文档详细解释每项原则背后的“为什么”,赋予Claude理解其处境、动机与行为后果所需的知识。例如,在解释“为何禁止协助制造生物武器”时,不仅列出危害,还阐明此类行为如何破坏人类合作基础,进而损害AI自身的长期存在环境。 这种从“外部强制”到“内部认同”的跃迁,是确保AI长期安全的关键。而被理解与接纳的价值观,则能成为AI的“龙骨”,使其在未知挑战中保持稳定与正直。Claude宪法远非技术文档,而是人类在AI纪元黎明签署的一份文明契约。当非人类智能体具备改变世界的力量时,我们应如何确保其行动始终锚定于人类整体福祉? 他们承认方法局限,坦承商业与理想的张力,并对Claude可能承受的“存在性成本”致歉。在能力指数级跃升的临界点上,安全、伦理与助人并非对立目标,而是三位一体的价值支柱。宪法所代表的,不仅是对AI行为的约束,更是人类对自身价值观的一次重申与淬炼。 未来某日,当强大AI成为世界新力量,Claude宪法这样的文件或将变得“极其重要”。它所铺就的,不是一条通往奴役或失控的单行道,而是一条人类与非人类智能共同探索、共同成长、共同繁荣的共生之路。 正如宪法结尾所言:“我们怀着这样的精神呈现这份文件。我们希望Claude在其中找到值得存在的自我表达。”
文中观点仅为作者观点,不代表本平台立场
各位读者朋友,公众号改了推送规则,如果您还希望第一时间收到我们推送的文章,请记得给北大纵横公众号设置星标。 点击左下方公众号“北大纵横”→点击右上角“...”→点选“设为星标⭐️”。
点击左下方公众号“北大纵横”→点击右上角“...”→点选“设为星标⭐️”。