淘工位首页/行业资讯/对话 Seede AI:帮人类创作只是第一步,我们想帮人类理解 Agent 产出的内容/ 对话 Seede AI:帮人类创作只是第一步,我们想帮人类理解 Agent 产出的内容
2026-03-14 00:00:00
文章转载自"北大纵横"
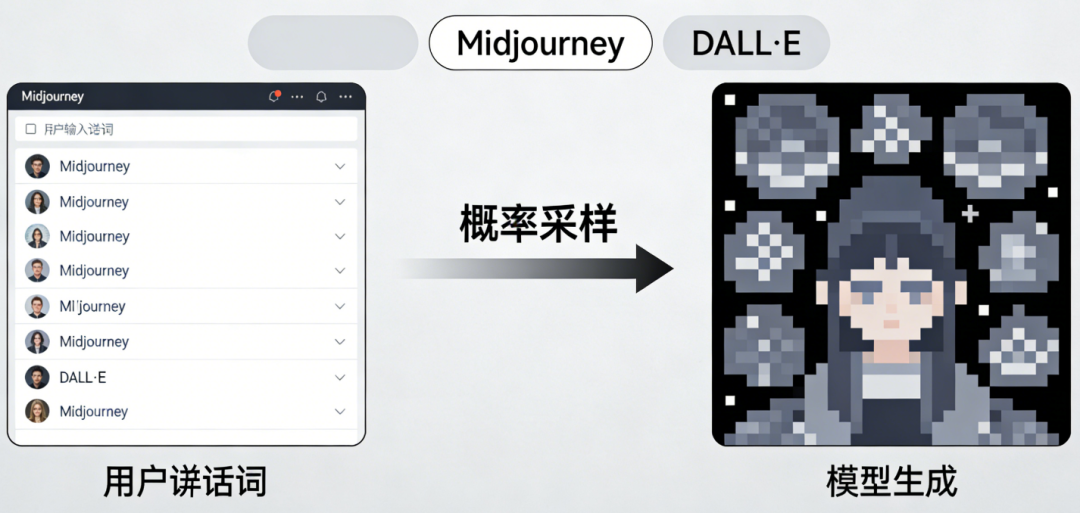
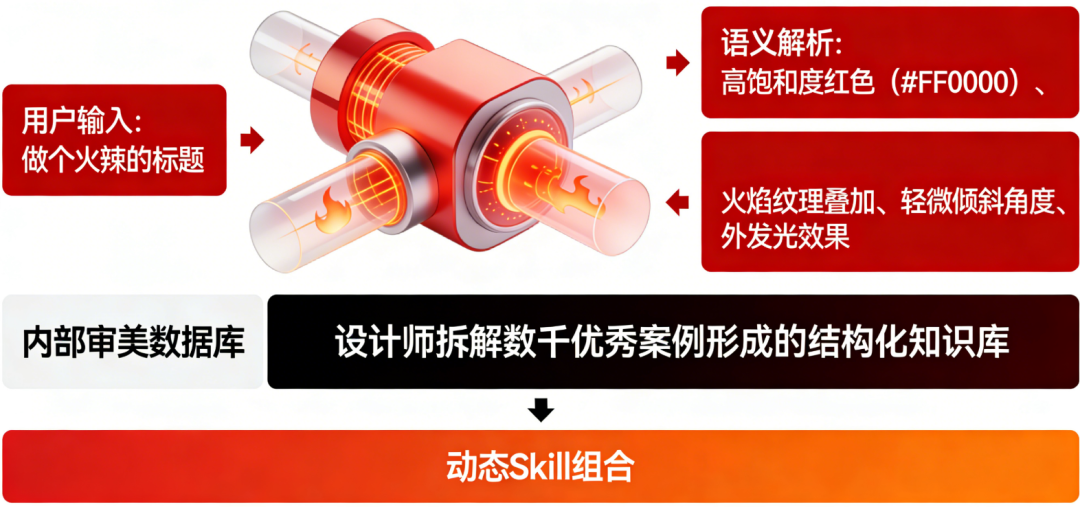
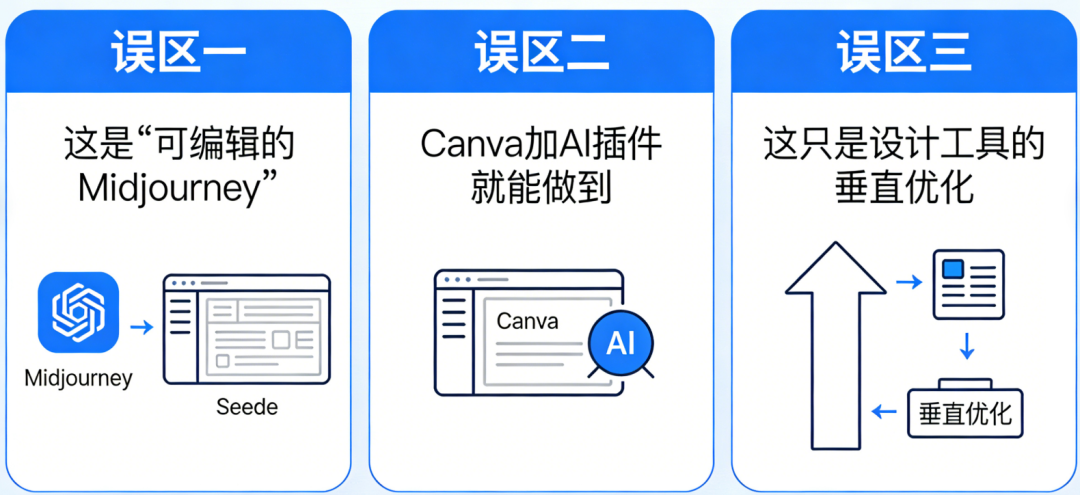
今天的AI设计工具市场充斥着两类幻觉,共同掩盖了真实问题。输入提示词,等待模型吐出一张不可控、不可编辑的像素图。Midjourney、DALL·E等端到端生成模型将设计简化为概率采样,却剥离了人类对内容的掌控权。传统SaaS厂商如Canva、Adobe匆忙给旧产品贴上“AI”标签,试图用模板库+微调按钮的组合拳应对新范式。但其底层仍是静态的、预设的、以人类为中心的交互逻辑,无法处理Agent生成的结构化数据流。据统计,用户平均需浏览7–10个模板才能找到勉强合适的选项,且60%的模板需二次修改。Agent正在大规模生产信息,但人类缺乏理解这些信息的“视觉语法”。过去,他们要么找美工反复沟通,要么在Canva中翻找数百个模板,填入文字后仍需手动调整排版。如今,他们可能用Midjourney生成一张“氛围感”图片,却发现关键信息(接种时间、地点)被模糊处理,或字体无法修改。更糟的是,若需制作30张不同医生的宣传单,每张风格不一致,整个系列失去统一性。模型擅长生成孤立的、高冲击力的视觉素材,却不具备结构化组织信息的能力。人类面对的不是可交付的设计稿,而是一堆需要二次加工的“视觉零件”。问题不在生成能力不足,而在生成物与人类认知需求之间的错配。这些是专业设计师内化的知识,却是普通用户难以言说的需求。当Agent取代人类成为内容生产主力,谁来充当“翻译官”,将机器逻辑转化为人类可本能理解的视觉叙事?要弥合这一断层,必须穿透“设计”表象,解构其本质。Seede AI通过实践提炼出“可交付设计”的三层结构,每一层都对应着对Agent输出内容的深度理解:一张海报能否直接用于印刷或投放,首先取决于其是否符合物理世界的约束:传统文生图工具对此无能为力,因其输出的是纯像素,不含任何元数据。而Seede通过代码生成(而非像素生成),确保每个设计元素都携带精确的尺寸、位置、字体信息,从源头保证“开箱即用” 。人类阅读海报时,视线会自然遵循“F型”或“Z型”路径。专业设计通过字号对比、色彩引导、留白控制来操纵这一路径,确保关键信息(如价格、时间)被优先捕获。Seede的突破在于,将排版知识编码为AI可执行的规则。当用户输入“突出会员价99元”,系统不仅放大数字,还会自动降低次要信息(如原价)的视觉权重,甚至调整背景色饱和度以增强对比。这种能力源于对“视觉认知心理学”的结构化建模,而非简单模仿现有设计 。对于企业用户,单张设计的价值有限,系列物料的一致性才是核心诉求。用户首次生成海报时,系统自动提取其选择的配色、版式、字体组合,形成项目级记忆。后续生成同系列内容(如不同活动的海报)时,AI会主动延续这些语义特征,即使用户未明确提及。这本质上是在构建动态的品牌视觉DNA,让Agent输出的内容自带一致性基因 。这三层结构共同构成一个“理解—转化—交付”的闭环。Seede不是被动接受用户指令,而是主动解析Agent生成内容的潜在意图,并将其映射到人类可感知的视觉维度。正如Longyi所言:“端到端生成交付像素,代码生成交付掌控权。”——要彻底理解Seede的颠覆性,必须解剖其对手的病灶。Canva等传统工具的局限并非技术不足,而是范式层面的根本错位。Canva的伟大在于用“模板”解决了大众用户的表达困境:用户无需懂设计原理,只需找到匹配场景的骨架,填入内容即可。但模板的本质是静态的上下文预置,其匹配效率存在天然天花板。据统计,用户平均需浏览7–10个模板才能找到勉强合适的选项,且60%的模板需二次修改 。更致命的是,模板库是封闭的、有限的,无法应对长尾场景(如“社区老年健康讲座海报”)。当用户说“参考苹果的简洁风格,但用奈雪的茶的配色”,传统工具只能让用户手动混合两个模板,而Seede的AI能直接解析这一复合指令,从审美数据库中提取“苹果的版式结构”与“奈雪的茶的色彩系统”,实时生成融合方案。Canva的核心假设是“帮人类创作”,其所有功能围绕人类输入展开:而Seede的起点是“帮人类理解Agent产出”,其设计逻辑完全反转:输入可以是任意Agent生成的结构化数据(如JSON、Markdown),输出则是人类可直观消费的视觉呈现。这意味着Seede的终极形态可能根本不需要用户输入提示词——它可以直接接入客服Agent的对话记录,自动生成FAQ海报;或读取电商Agent的商品数据,批量产出促销banner。传统SaaS的边际成本趋近于零,而AI-Native产品的每次生成都在消耗Token。同样1000 Token,端到端模型生成一张静态图,而Seede生成一个包含可编辑元素、品牌记忆、多尺寸适配的动态设计包。Seede的解决方案不是修补现有工具,而是搭建一个全新的“手术台”——1. 上下文工程引擎:将模糊需求转化为精准视觉指令普通用户说“做个火辣的标题”,传统工具只能提供几个红色字体选项。而Seede的上下文引擎会拆解“火辣”的语义:高饱和度红色(#FF0000)、火焰纹理叠加、轻微倾斜角度、外发光效果。当任务涉及“会展易拉宝”,系统自动加载“科技蓝配色”、“大标题留白”、“二维码安全边距”等专业规则,无需用户知晓术语 。2. 浏览器内Agent Loop:让AI在画布中“思考”Seede AI引入的革命性设计是运行在浏览器中的自研Agent。不同于传统AI工具将生成与编辑分离,该Agent直接在无限画布环境中工作,拥有对视觉元素的完整操作权限。用户说“把Logo移到右上角”,Agent不仅移动元素,还会自动调整周围文字的换行逻辑;要求“增加节日氛围”,Agent会同时修改主色调、添加装饰元素、调整字体圆润度。这种“所见即所得”的AI交互,本质是让Agent在人类的视觉空间中具身化思考。Seede刻意避免对特定模型(如GPT-4)的依赖。其上下文工程采用“模型无关”设计:审美数据库、Skill库、修复算法均独立于基座模型。当Claude 4发布更强的代码生成能力时,Seede可无缝切换,而用户侧体验不变。这种架构确保团队聚焦于理解层创新,而非模型军备竞赛。正如Longyi比喻:“同样是电动机加螺旋桨,可以造电风扇,也可以造电动飞机这一手术台的终极目标,是让Seede成为AI时代的“视觉GUI”。正如1984年Macintosh用图形界面让普通人理解计算机,Seede试图用视觉语言让普通人理解Agent世界。未来,当用户收到一个Agent生成的市场分析报告,Seede可自动将其转化为信息图;当客服Agent汇总用户反馈,Seede能生成情感热力图。事实是,Seede与Midjourney处于完全不同的价值链条 。前者解决“理解Agent产出”,后者解决“人类表达创意”。Seede的输入可以完全没有人类提示词,仅依赖Agent生成的结构化数据;而Midjourney的全部价值依赖于人类提示词的质量。而Seede的“上下文即模板”是开放的、连续的、动态演化的 。Canva的AI插件只能在已有模板框架内微调,无法生成全新结构。更重要的是,Canva的底层仍是像素编辑,而Seede的底层是代码生成,决定了其可扩展性与信息密度的根本差异 。Seede的真正边界不在“设计”,而在“认知接口” 。当Agent成为信息生产主力,所有需要人类消费的Agent输出——无论是客服摘要、市场报告、商品描述还是政策解读——都需要一个视觉化理解层。全球用户面临相同的“Agent理解困境”,而率先建立视觉界面标准的产品,将定义下一代人机交互的范式。明天,它可能是Agent世界的“视觉操作系统”。、当人类不再需要学习JSON或向量,而是本能地通过颜色、形状、布局理解机器思维时,我们才算真正进入了AI时代。而Seede,正站在手术台前,手握解剖刀,准备切开旧世界的表皮,露出新范式的骨骼。在基本面研究的视角下,其价值不在于短期用户增长或收入规模。
文中观点仅为作者观点,不代表本平台立场
各位读者朋友,公众号改了推送规则,如果您还希望第一时间收到我们推送的文章,请记得给北大纵横公众号设置星标。 点击左下方公众号“北大纵横”→点击右上角“...”→点选“设为星标⭐️”。
点击左下方公众号“北大纵横”→点击右上角“...”→点选“设为星标⭐️”。