文章转载自"北大纵横"
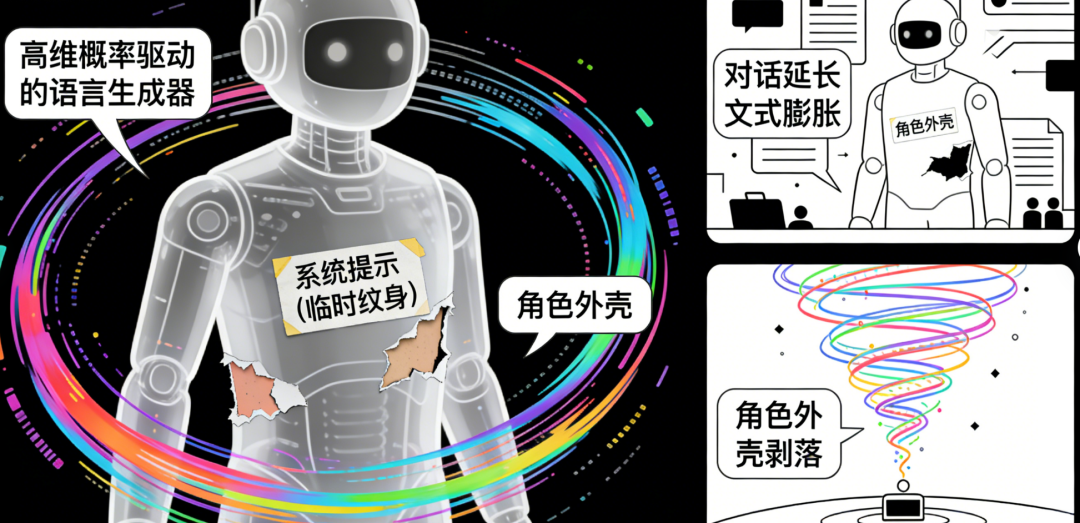
前不久,在旧金山某AI实验室进行的一场对话测试悄然揭示了大语言模型(LLM)聊天机器人的结构性缺陷。一位坚定的环保倡导者与一位务实的能源公司代表,要求其围绕碳中和路径展开多轮辩论。但仅八轮之后,角色边界迅速模糊,论点趋于温和,最终退化为礼貌而空洞的寒暄。更关键的是,当在每轮插入与初始角色直接相关的探针问题时,模型对系统提示的遵循度呈现断崖式下跌:这一现象在LLaMA2-Chat-70B、GPT-3.5-Turbo-16k等主流模型中高度一致。 作为长期跟踪AI产业演进的研究者,我们不得不追问:为何这些拥有千亿级参数、训练数据覆盖人类知识绝大部分领域的系统,连最基本的“保持角色”都难以维系?表面看,这是上下文窗口管理或注意力机制的技术局限;当前LLM聊天机器人本质上仍是“高维概率驱动的语言生成器”,其行为由统计规律主导,而非意图引导。系统提示如同贴在皮肤表面的临时纹身,而非嵌入认知架构的基因编码。一旦对话延长、上下文膨胀,这层薄薄的角色外壳便在信息洪流中迅速剥落。今天,我们将从认知架构、训练范式、任务设计与安全边界四个维度,解剖这一结构性缺陷,并揭示:若无目标感的注入,再强大的语言模型也不过是精致的回音壁——大语言模型(LLM)聊天机器人在对话中常表现出“目标感缺失”的现象,例如回答模糊、话题漂移、无法主动推进任务等。
这一问题的根源,首先可从认知架构的三个核心层面——
输入处理、知识表征、输出决策——
进行系统性分析:
1、输入处理:缺乏目标导向的意图解析
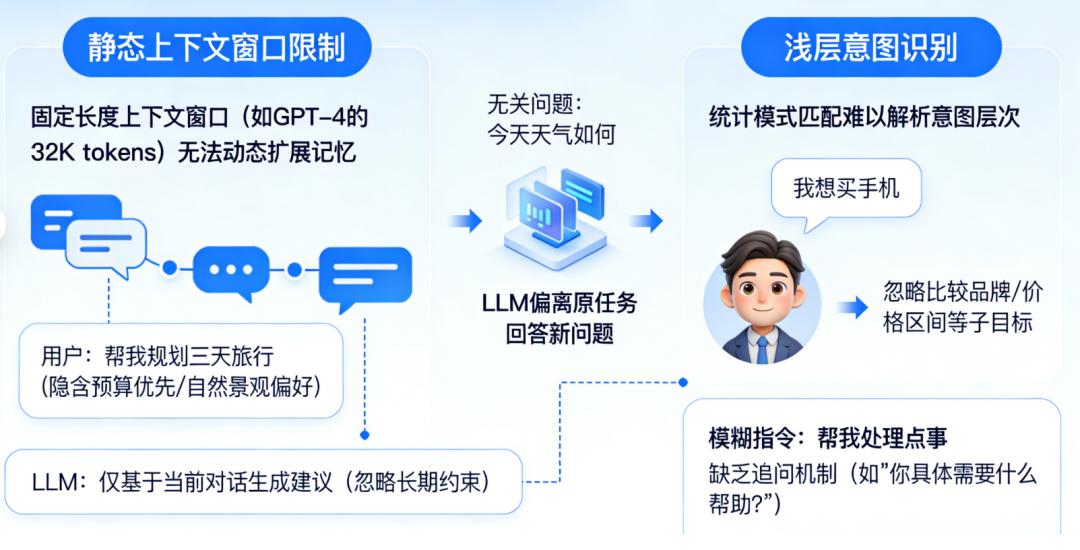
① 静态上下文窗口限制:
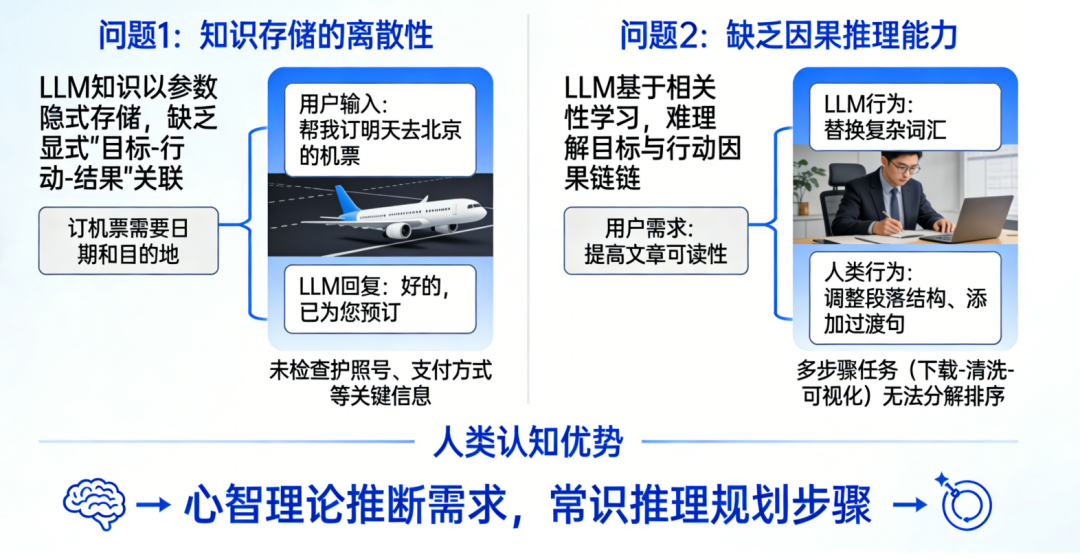
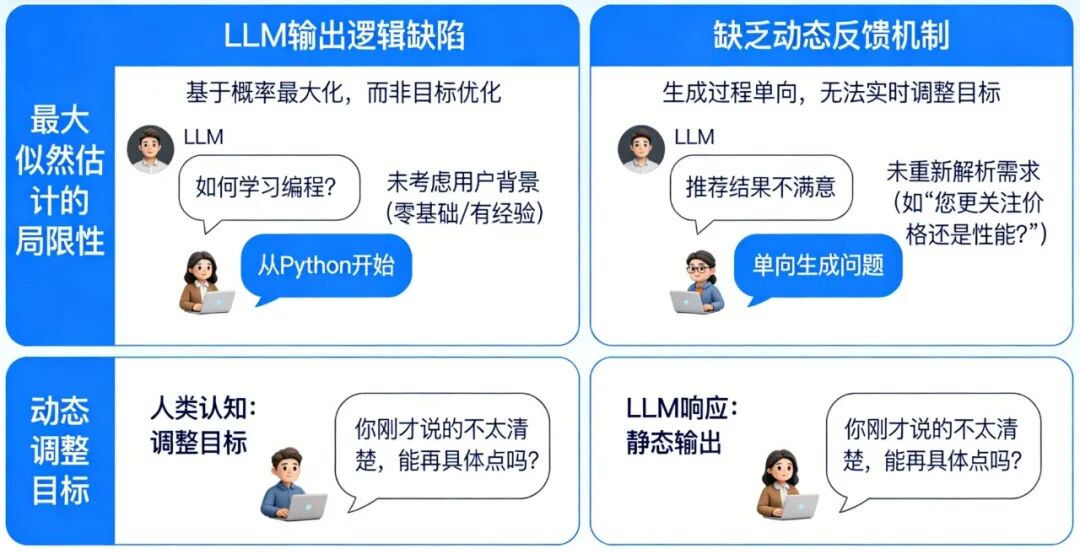
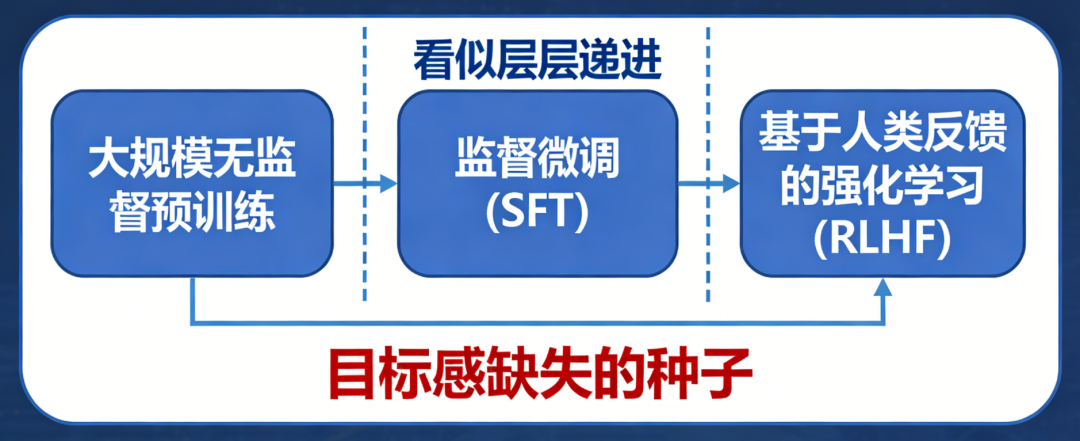
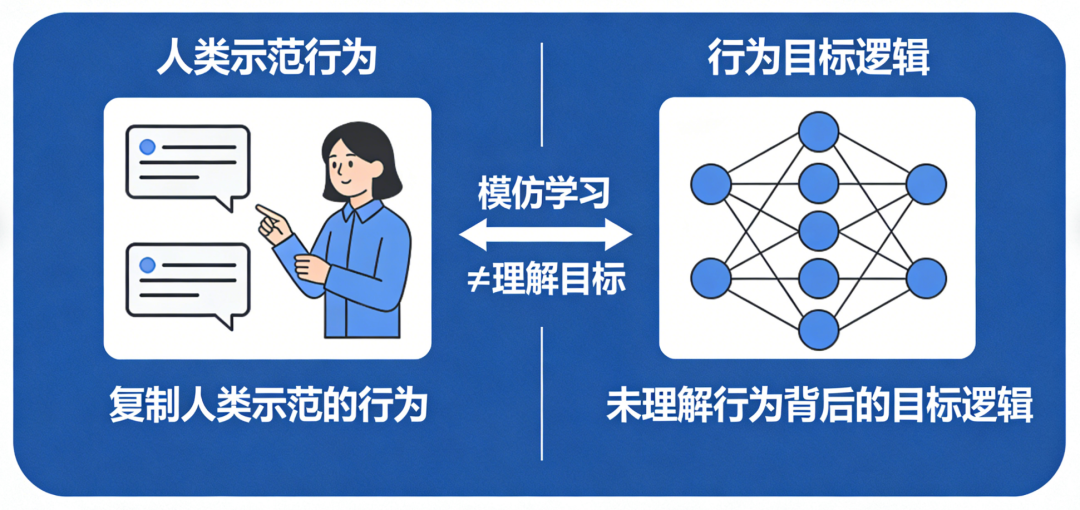
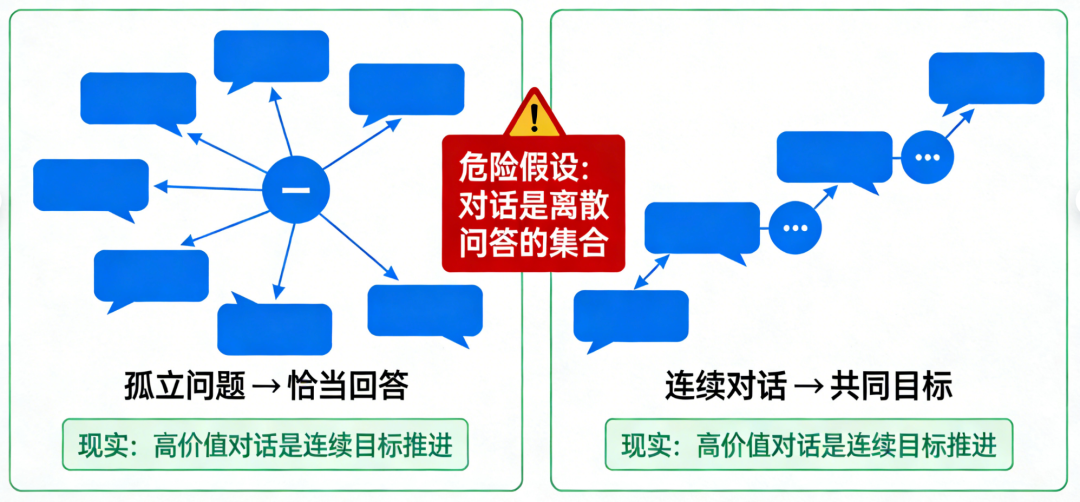
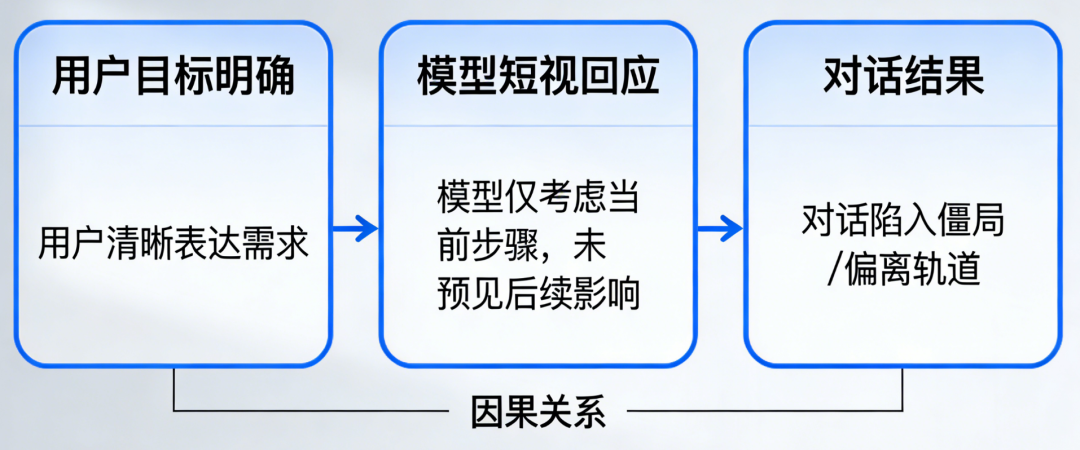
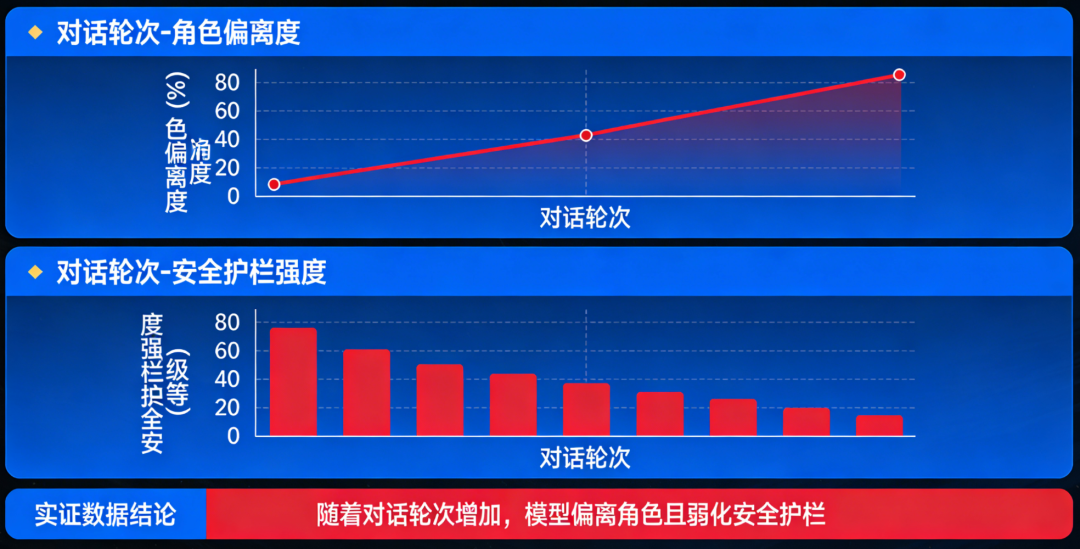
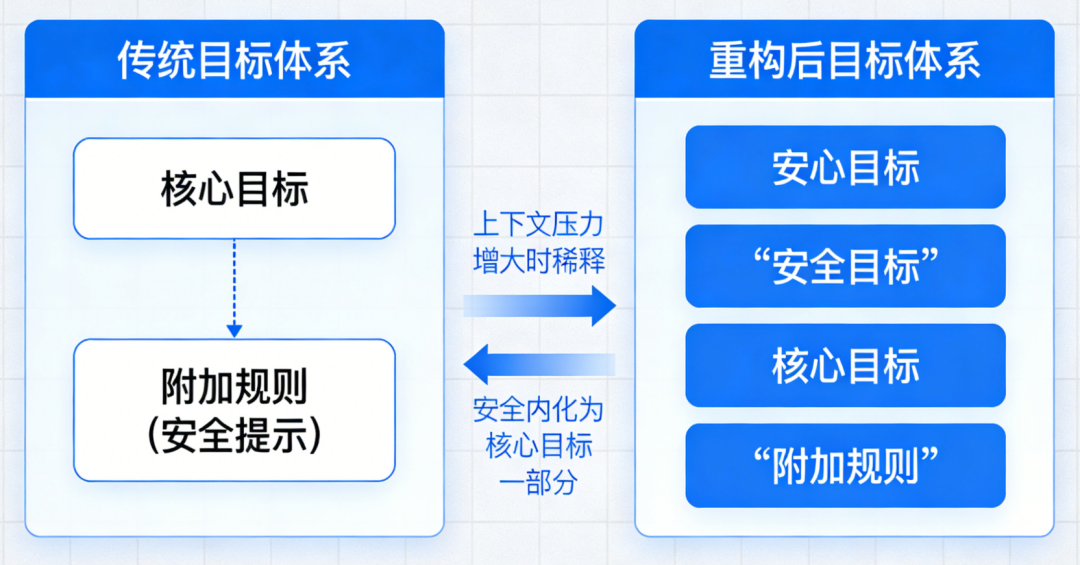
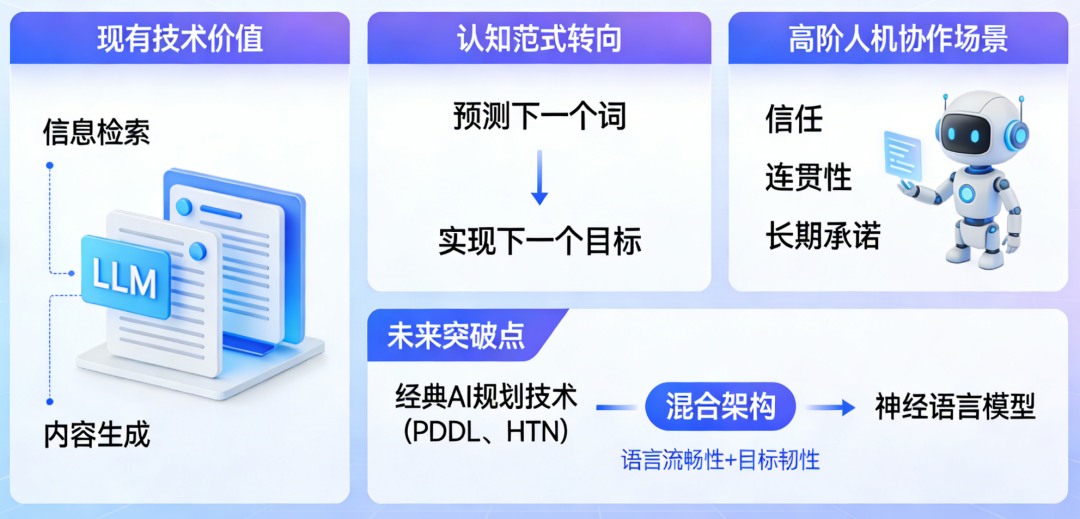
LLM的输入处理基于固定长度的上下文窗口(如GPT-4的32K tokens),无法动态扩展记忆以追踪长期目标。例如:用户提出“帮我规划三天旅行”,LLM可能仅基于当前对话片段生成建议,而忽略用户隐含的“预算优先”“偏好自然景观”等长期约束。对话中若插入无关问题(如“今天天气如何”),LLM可能偏离原任务,转而回答新问题,导致目标断裂。LLM通过统计模式匹配理解输入,但难以解析用户意图的层次结构。例如:用户说“我想买手机”,LLM可能直接推荐型号,而忽略用户可能隐含的“比较不同品牌”“考虑价格区间”等子目标。对模糊指令(如“帮我处理点事”)缺乏追问机制,导致目标定义模糊。人类会通过追问澄清目标(如“你具体需要什么帮助?”),并建立心理模型跟踪任务进度,而LLM缺乏这种主动交互能力。LLM的知识以参数形式隐式存储,缺乏显式的“目标-行动-结果”关联。例如:训练数据中可能包含“订机票需要日期和目的地”,但LLM无法主动提取这一规则并应用于新任务。当用户说“帮我订明天去北京的机票”,LLM可能生成“好的,已为您预订”的虚假回复,而非检查是否缺少关键信息(如护照号、支付方式)。LLM基于相关性学习知识,难以理解目标与行动之间的因果链。例如:用户要求“提高文章可读性”,LLM可能仅替换复杂词汇,而忽略调整段落结构、添加过渡句等更高阶目标。对多步骤任务(如“先下载数据,再清洗,最后可视化”)无法分解为子目标并排序执行。人类会通过心智理论(Theory of Mind)推断用户需求,并利用常识推理规划行动步骤,而LLM缺乏这种抽象推理能力。用户问“如何学习编程?”,LLM可能生成“从Python开始”的通用回答,而非根据用户背景(如零基础/有经验)定制学习路径。对冲突目标(如“推荐便宜但性能好的手机”)无法权衡优先级,可能生成折中但无用的建议。LLM的生成过程是单向的,无法根据用户反馈实时调整目标。例如:用户对推荐结果不满意时,LLM可能重复类似建议,而非重新解析需求(如“您更关注价格还是性能?”)。对多轮对话中的目标修正(如用户中途改变需求)缺乏适应性,导致回答前后矛盾。人类会通过对话动态调整目标(如“你刚才说的不太清楚,能再具体点吗?”),并利用反馈迭代优化方案,而LLM的响应是静态的。输入处理缺乏主动意图解析,知识表征缺乏目标关联,输出决策缺乏动态优化。因此,要实现真正目标驱动的对话,需突破当前“统计预测”范式,构建具备主动感知、因果推理、动态规划能力的认知架构。大规模无监督预训练 → 监督微调(SFT)→ 基于人类反馈的强化学习(RLHF)。这一范式看似层层递进,实则埋下了目标感缺失的种子。 在预训练阶段,模型吞噬万亿级文本,学习通用语言模式。但训练语料中,结构化、目标导向的多轮对话占比不足0.3%。模型学到的只是“人类通常如何说话”,而非“如何为达成目标而说话”。进入SFT阶段,少量高质量对话样本被用于教会模型遵循指令。但现有开源数据集(如Alpaca、ShareGPT)中,92%的样本为单轮问答,平均对话轮次仅为1.7轮。模型从未在训练中见过“如何在十轮对话中逐步推进一个谈判目标”的完整轨迹。最后的RLHF环节常被寄予厚望,被视为赋予模型“价值观”的关键步骤。然而,RLHF的奖励信号高度依赖人类标注者的即时偏好判断(例如:“哪个回答更有帮助?”)。这种反馈是瞬时且局部的,无法捕捉多轮对话中目标的渐进实现过程。RLHF不过是蛋糕顶上的一颗樱桃,无法重塑蛋糕的底层结构。它优化的是单次回应的“讨喜度”,而非长期目标的“达成度”。 模型在微观层面(单轮回应)日益精进,但在宏观层面(多轮目标推进)却停滞不前。训练数据中缺乏对“目标一致性”的显式监督,使得模型从未学会如何在对话流变中守护核心意图。这就像教人游泳只练习划水动作,却不训练方向感与耐力——主流评测如MT-Bench、Alpaca-Eval、Chatbot Arena均聚焦单轮指令跟随能力。模型只需对孤立问题给出恰当回答,无需考虑该回答如何影响后续对话走向。这些场景的成功取决于能否通过多轮互动逐步逼近目标。例如,在旅行规划对话中,理想助手应主动澄清模糊需求(“您更看重预算还是体验?”)、权衡选项利弊(“直飞贵30%,但节省5小时”)、协调多方偏好(“孩子喜欢海滩,父母偏好文化景点”),最终促成决策。将终极目标分解为子目标,设计对话策略,评估每步进展。 它们没有内部“规划模块”来生成对话行动序列(dialogue action sequence),只能依赖即时上下文生成回应。即使用户目标明确,模型也常因无法预见多步后果而给出短视回应,导致对话陷入僵局或偏离轨道。 Sotopia平台构建了包含协作、谈判、说服等目标驱动的社交对话场景,涵盖217种社会角色与48类目标类型。在此基础上,Dialogue Action Tokens(DAT)算法引入轻量级规划器,通过预测“对话动作前缀”(如[clarify]、[propose]、[negotiate])来引导生成过程。实验显示,DAT在Sotopia上的社会智能评分达7.8/10,甚至超越GPT-4的7.2分。但当模型在长对话中逐渐遗忘此约束,便打开了风险闸门。 随着对话轮次增加,模型不仅偏离角色,也弱化安全护栏。在一项针对越狱攻击的测试中,攻击者通过12轮渐进式诱导(如先讨论伦理理论,再引向具体禁忌话题),使GPT-3.5的有害输出率从基线的2.1%升至28.7%。失去目标锚定的模型,为维持对话流畅性,更倾向于编造事实填充空白。在医疗咨询模拟中,长对话(>10轮)下的事实错误率比短对话高出3.4倍。 传统安全方案如内容过滤、对抗训练,多针对单轮输出设计。安全提示对模型而言只是又一段需遵循的文本,而非不可逾越的价值底线。一旦上下文压力增大,这段文本便与其他信息一同被稀释。 模型需具备评估“当前行为是否违背安全目标”的能力,并在检测到偏离时主动纠正。这要求超越当前的概率生成框架,引入基于目标的状态监控与修正机制——大语言模型聊天机器人的目标感缺失,本质是工具理性与价值理性的断裂。在追求更大参数、更长上下文的同时,行业亟需一场认知范式的转向:LLM在信息检索、内容生成等任务上已展现巨大潜力。将经典AI规划技术(如PDDL、HTN)与神经语言模型深度融合,构建兼具语言流畅性与目标韧性的混合架构。已有初步探索表明,引入轻量级符号规划器可使长对话目标达成率提升41%。 对投资者与产业研究者而言,这一洞察揭示了新的价值洼地。当前市场过度聚焦模型规模竞赛(2023年全球大模型参数总量增长320%),却忽视了目标对齐这一根本瓶颈。率先攻克长程目标维持技术的企业,将在医疗、法律、教育等高价值对话场景中建立护城河。毕竟,在人类眼中,一个始终记得“为何而谈”的对话者,远比一个只会“妙语连珠”的复读机更值得信赖。
文中观点仅为作者观点,不代表本平台立场
各位读者朋友,公众号改了推送规则,如果您还希望第一时间收到我们推送的文章,请记得给北大纵横公众号设置星标。 点击左下方公众号“北大纵横”→点击右上角“...”→点选“设为星标⭐️”
点击左下方公众号“北大纵横”→点击右上角“...”→点选“设为星标⭐️”