文章转载自"北大纵横"
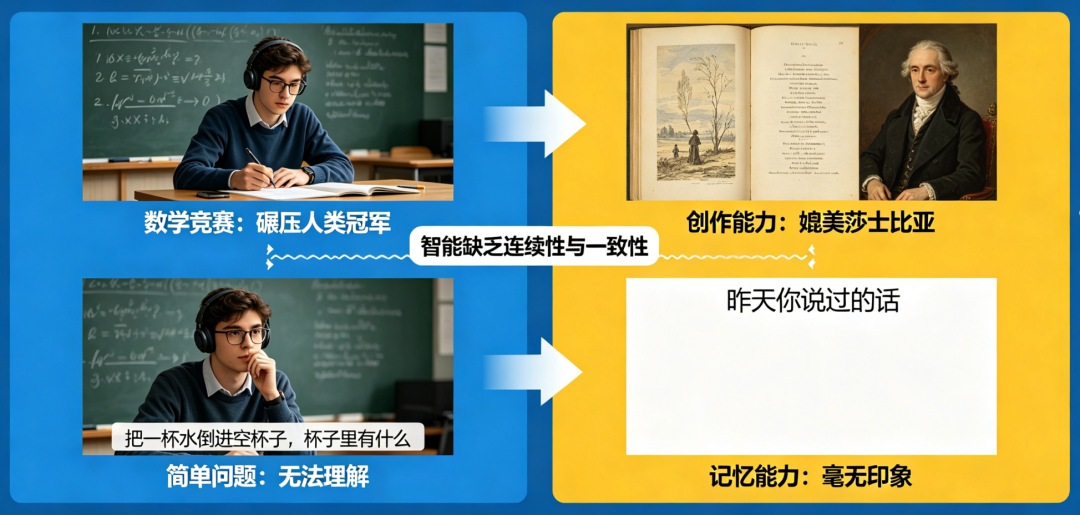
德米斯·哈萨比斯(Demis Hassabis)发现:一个虚拟角色在模拟环境中自主探索、规划路径,并根据用户指令动态调整策略。其画面特别流畅,逻辑严密,仿佛已逼近通用人工智能(AGI)的临界点。 它无法解释为何刚执行的动作不再适用,也无法调用几分钟前的成功经验。 作为全球最接近AGI的实验室掌舵人,哈萨比斯一针见血地指出:“今天的系统是‘参差不齐的智能’(Jagged Intelligences)——在某些任务上惊艳绝伦,换个问法却连基础逻辑都崩塌。”这种忽强忽弱的智能波动,不是技术演进的阵痛,而是结构性危机的征兆。若放任其发展,AGI非但不会成为人类文明的加速器,反而可能演变为一场不可控的认知灾难。 而破解这一困局的关键,不在更大的参数、更强的算力,而在一个被长期忽视的核心组件:当前主流大模型的表现,恰如一位患有间歇性失忆症的天才。它能在数学竞赛中碾压人类冠军,却无法理解“如果你把一杯水倒进空杯子,杯子里有什么”;它能写出媲美莎士比亚的十四行诗,却对“昨天你说过的话”毫无印象。 这种剧烈波动并非能力不足,而是智能缺乏连续性与一致性的体现。部署后,它无法像人类一样通过日常交互持续吸收新信息。这意味着,无论模型多强大,其认知始终停留在“过去时”。例如,2024年某医疗AI在训练数据未包含新冠变异株XBB.1.5的情况下,仍向用户推荐已失效的抗病毒方案,造成潜在风险。 128K、1M甚至更长的上下文,本质是用算力换记忆,效率极低。更致命的是,模型并不真正“理解”哪些信息重要、哪些可遗忘——它只是机械拼接token,如同把图书馆所有书页撕碎后随机粘贴。实测显示,当上下文超过50K tokens时,关键信息召回率下降超40%,噪声干扰显著上升。 人类记忆分为感觉记忆、短期记忆、长期记忆,并通过海马体进行筛选与巩固。所有信息要么被丢弃(因超出上下文),要么被平等对待(导致噪声淹没信号)。一个客服AI可能在上午成功处理了某用户的退款请求,下午同一用户再次咨询时,却要求其重新提供订单号、身份证明等全部信息。 它的强大建立在海量数据的统计拟合之上,而非真正的理解与积累。要治愈AI的“认知癫痫”,必须重建其记忆系统。
这不是简单增加存储容量,而是构建一套类脑的记忆机制。
我们可以将其解剖为3个核心层面:
1. 持久化记忆存储:从“无状态”到“有历史”
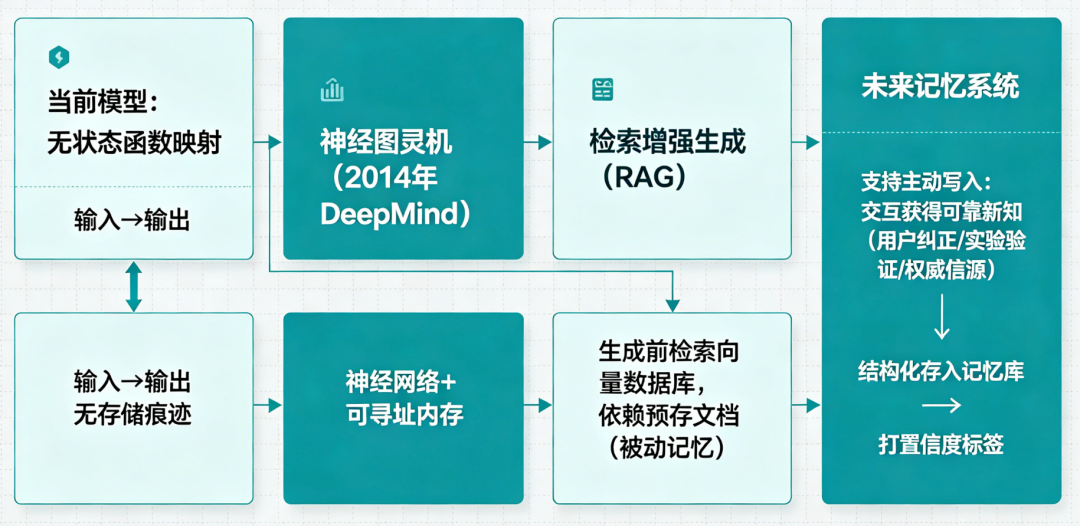
当前模型本质上是无状态的函数映射:
输入→输出,中间不留痕迹。
真正的智能体必须具备持久化记忆库——
一个可读写、可更新、可索引的外部存储系统。
早在2014年,DeepMind就提出神经图灵机(Neural Turing Machine),尝试将神经网络与可寻址内存结合。它依赖预存文档,无法自主学习新事实。 未来的记忆系统需支持主动写入:当AI通过交互获得可靠新知(如用户纠正、实验验证、权威信源),应能将其结构化存入记忆库,并打上置信度标签。例如,若用户告知“我过敏花生”,系统不仅记住该事实,还应关联到饮食建议、药品禁忌等衍生知识。这种机制已在MemGPT等开源项目中初步实现,但尚未形成工业级标准。 人类通过睡眠实现记忆巩固——海马体将短期记忆回放,筛选重要信息,整合进新皮层的长期知识网络。哈萨比斯在访谈中明确提到:“大脑在睡眠中‘回放’白天的记忆……也许我们需要类似机制。”更重要的是,它能让AI从具体案例中提炼模式,实现元学习(meta-learning)。例如,多次处理医疗咨询后,系统可归纳出“症状-疾病-治疗”的推理框架,而非仅记住孤立病例。Google DeepMind在2024年发布的“DreamerV3”已展示此类能力:在强化学习环境中,通过离线回放提升策略泛化性达37%。人类能根据当前任务,精准调取相关经验,忽略无关信息。系统需理解当前任务的目标、约束、历史上下文,动态决定:需要哪类记忆?(事实、流程、偏好、教训);时间范围?例如,在规划旅行时,AI应自动调取用户过往偏好(“讨厌红眼航班”)、预算限制、签证要求等,而非让用户重复输入。这种个性化、任务导向的记忆调用,才是智能体“懂你”的基础。微软Copilot在2025年初测试的“Personal Context Engine”已初步实现此功能,用户任务完成效率提升28%。这一范式带来惊人成果(如GPT-4),也掩盖了架构缺陷。 在资本追逐“更大更强”的狂潮中,这类需要长期投入的基础研究被边缘化。2023—2024年,全球Top 10 AI实验室中,仅DeepMind和Anthropic设有专职记忆架构团队,其余均聚焦模型压缩或推理优化。正如哈萨比斯所言:“未来几年,能发明全新算法构思的实验室将胜出。”——用户交互数据成为私有资产,用于迭代模型,但不反哺个体用户的记忆。你的聊天记录属于公司,而非你与AI共建的认知资产。 这种模式下,厂商无意开发开放、持久的个人记忆系统——Meta的Llama系列虽开源,但其配套记忆管理工具至今未开放;Google的Gemini Ultra虽支持长上下文,但用户无法导出或迁移个人记忆。 这些问题无标准答案,需跨学科协作(认知科学、密码学、分布式系统)。而当前AI研发仍以“端到端黑箱”为主流,排斥模块化设计。记忆系统要求透明、可干预的架构,与主流范式格格不入。78%的AI工程师认为“记忆模块会破坏模型端到端优化的简洁性”。
文中观点仅为作者观点,不代表本平台立场
各位读者朋友,公众号改了推送规则,如果您还希望第一时间收到我们推送的文章,请记得给北大纵横公众号设置星标。 点击左下方公众号“北大纵横”→点击右上角“...”→点选“设为星标⭐️”
点击左下方公众号“北大纵横”→点击右上角“...”→点选“设为星标⭐️”