

Deepseek 将连续5天发布开源成果:首秀来了!





FlashMLA是什么?
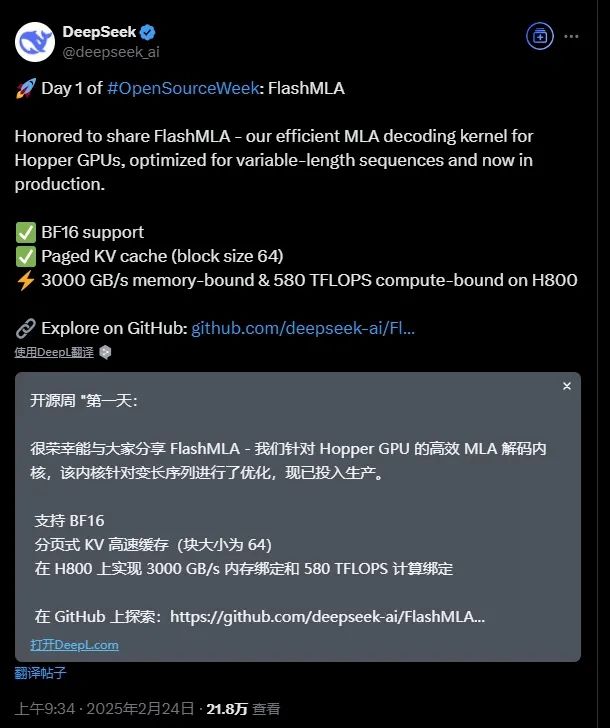
由DeepSeek于2025年2月24日开源的高性能AI推理加速工具
定位:专为 Hopper架构GPU(如H100/H200) 设计的注意力计算加速工具,对标英伟达的FlashAttention。 核心技术:通过优化 KV缓存管理 和 并行计算策略,显著减少内存占用,提升计算效率。
FlashMLA能干什么?
大模型推理加速
长文本处理:支持 百万级Token 的长上下文推理(如代码生成、文档分析),显存占用降低 50%+。
性能突破:在H800 GPU上,计算速度达 580 TFLOPS,带宽达 3000 GB/s,远超传统方法。
降低推理成本
显存优化:采用 分页KV缓存(类似虚拟内存分页),灵活管理显存,避免OOM(内存溢出)。
多设备支持:单卡处理更长序列,减少分布式部署需求,节省硬件成本。
开发者友好
易集成:提供Python API,支持PyTorch,3行代码即可调用。
兼容性:支持BF16数据类型,适配主流大模型架构(如LLaMA、DeepSeek系列
FlashMLA的应用场景
FlashMLA最直接的应用场景是 大规模 AI 模型推理,尤其是在 NLP、语音识别、推荐系统 等领域,将带来显著优化:
大语言模型(LLM)推理:加速 Transformer 计算,提高推理吞吐量;
机器翻译服务(MT):更快的文本处理能力,减少计算资源消耗,未来实时翻译长文或聊天,会像追剧刷字幕一样流畅。
语音识别和合成(ASR):优化长文本推理,降低推理延迟;未来语音转文字超精准,还能生成自然语音,简直是懒人福音。
聊天机器人&虚拟助手:快速生成超自然回复,随时随地陪你聊,感觉就像闺蜜在线。
文本摘要工具:长文档秒变精华摘要,工作学习效率翻倍,省时又省心。
推荐系统(RecSys):高效处理大规模数据,提高推荐精准度。
实时交互式任务:如智能客服、代码生成,减少延迟并提升用户体验。
长序列处理:优化长文本生成(如文档创作、翻译),避免显存瓶颈。
低成本推理服务:通过提升硬件利用率,降低企业部署大模型的算力门槛。



